Understanding how people’s experiences unfold over time is a key challenge in modeling human dynamics. In my latest publication, A Gentle Introduction and Application of Feature-Based Clustering with Psychological Time Series, my co-authors and I introduce feature-based time series clustering as a powerful method to tackle this challenge. This approach provides researchers with a flexible, interpretable, and practical tool to uncover meaningful patterns in complex psychological data.
Why Feature-Based Clustering?
Human (psychological) data collected through methods like the Experience Sampling Method (ESM) often come with unique challenges, such as multivariate structures, structurally missing data, and non-linear trends. Traditional approaches to clustering, which rely heavily on model parameters, can struggle to accommodate these complexities.
Feature-based clustering is a common technique accross disciplines but has thusfar received little direct application in psychological time series. Yet, the technique fits the literature exceptionally well because it directly leverages dynamic features—such as variability, trends, and temporal dependencies. These are commonly used for theory testing and are easily derived from the data itself. This allows researchers to:
- Mix and match features to fit their research questions.
- Avoid restrictive model assumptions.
- Produce clusters that are easier to interpret and directly linked to (psychological) theory.
A Step-by-Step Illustration
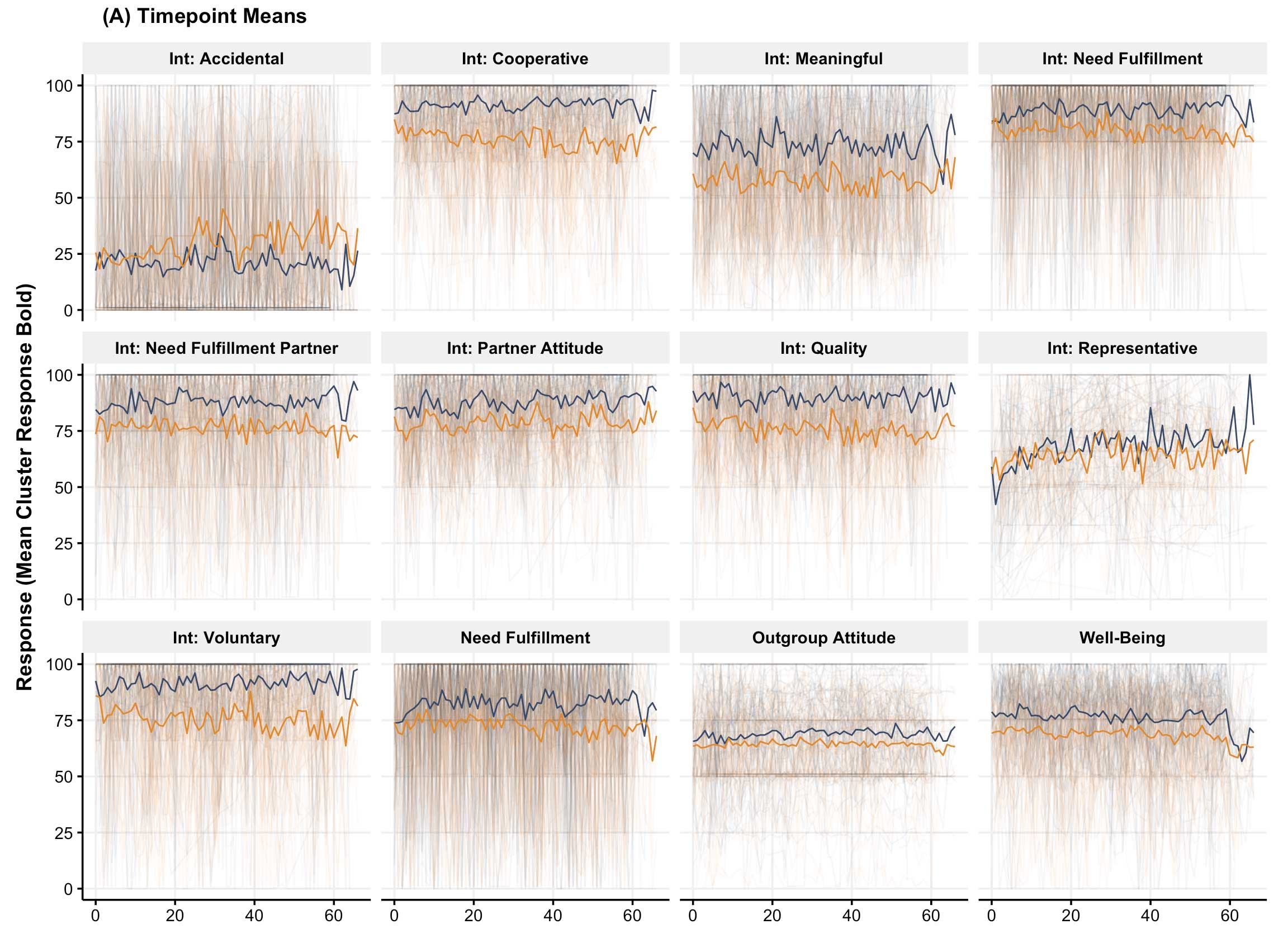
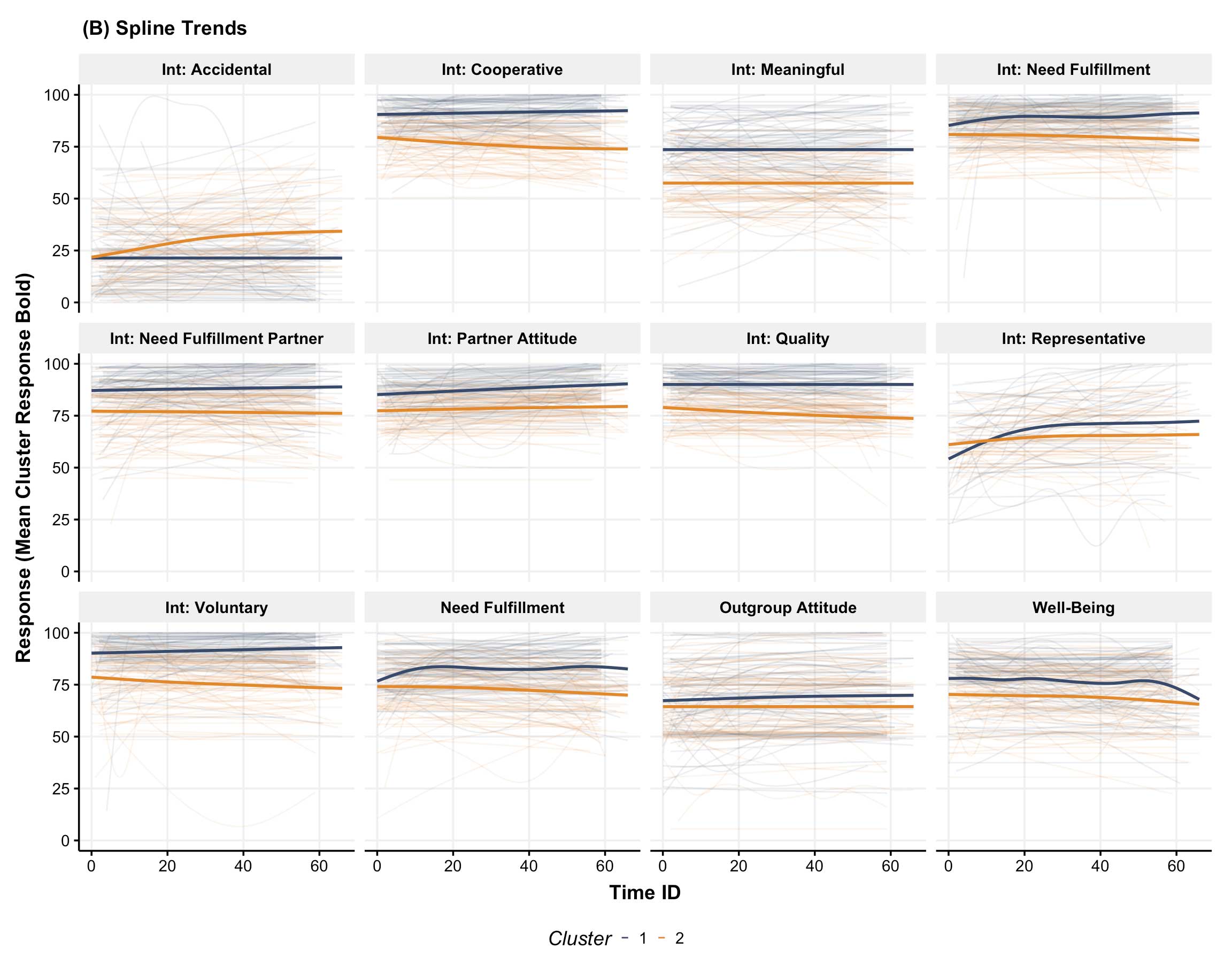
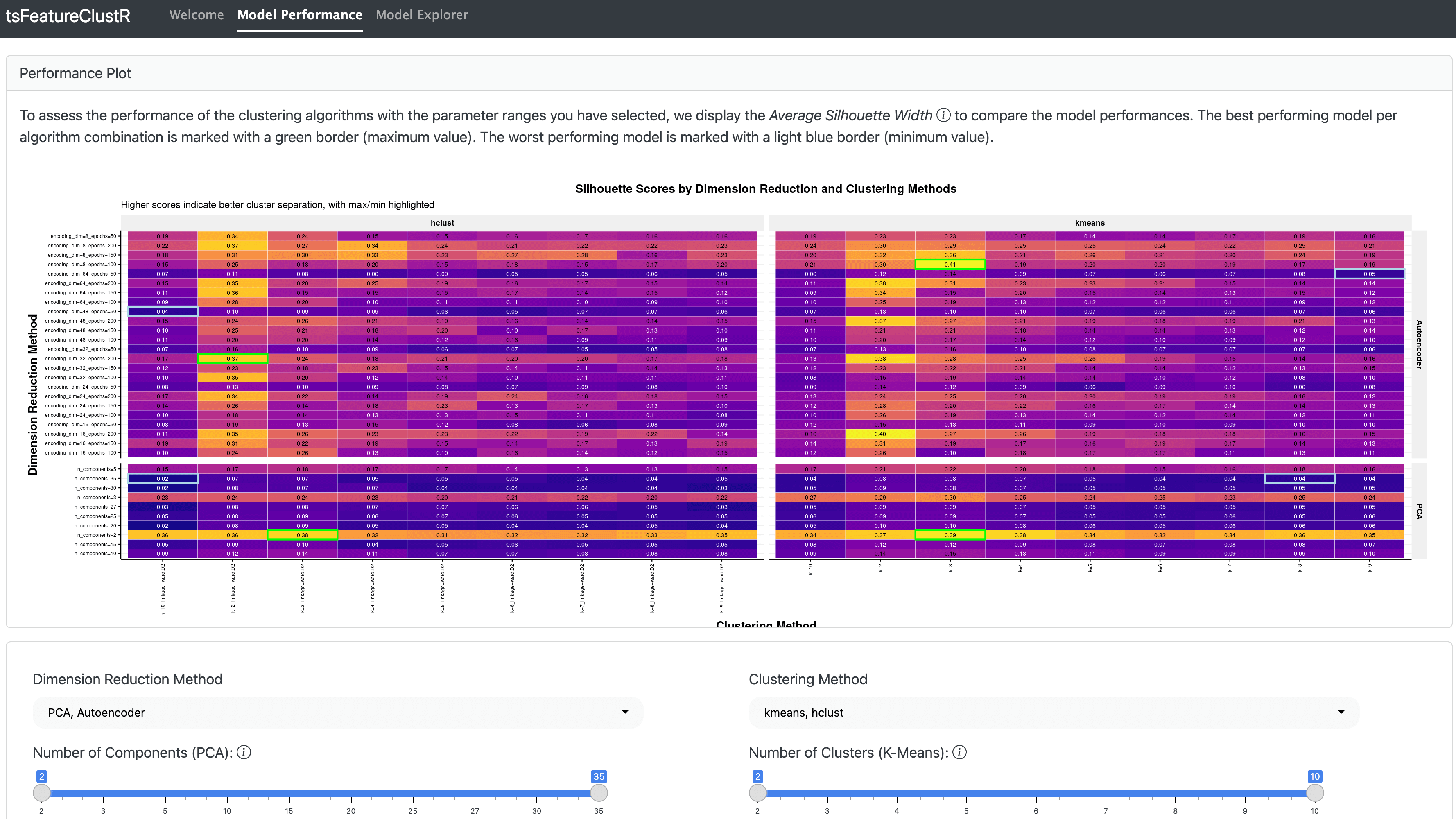
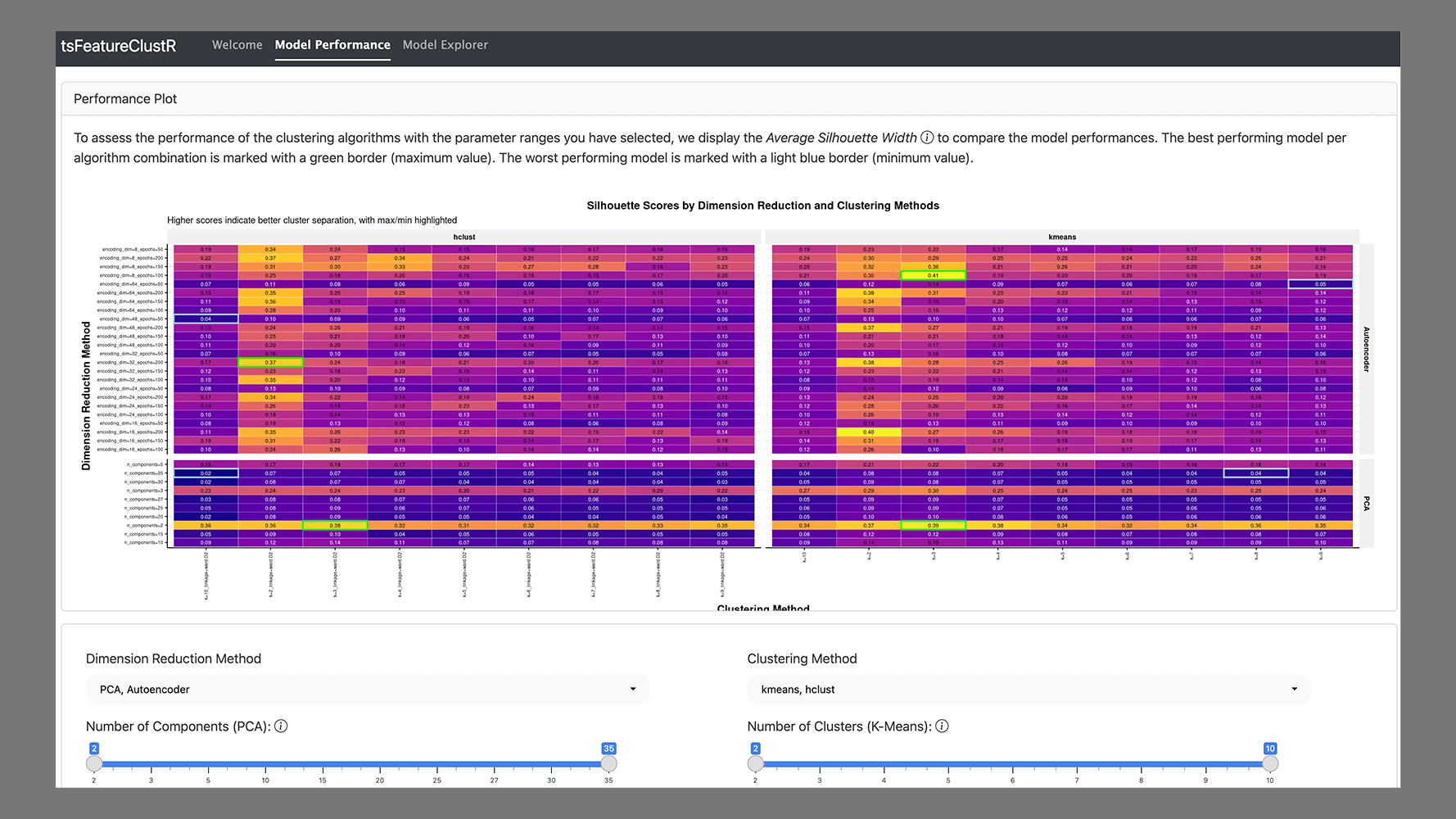
In the paper, we apply this method to data tracking the daily interactions and well-being of migrants in the Netherlands. Here’s a snapshot of the process in its simplest form:
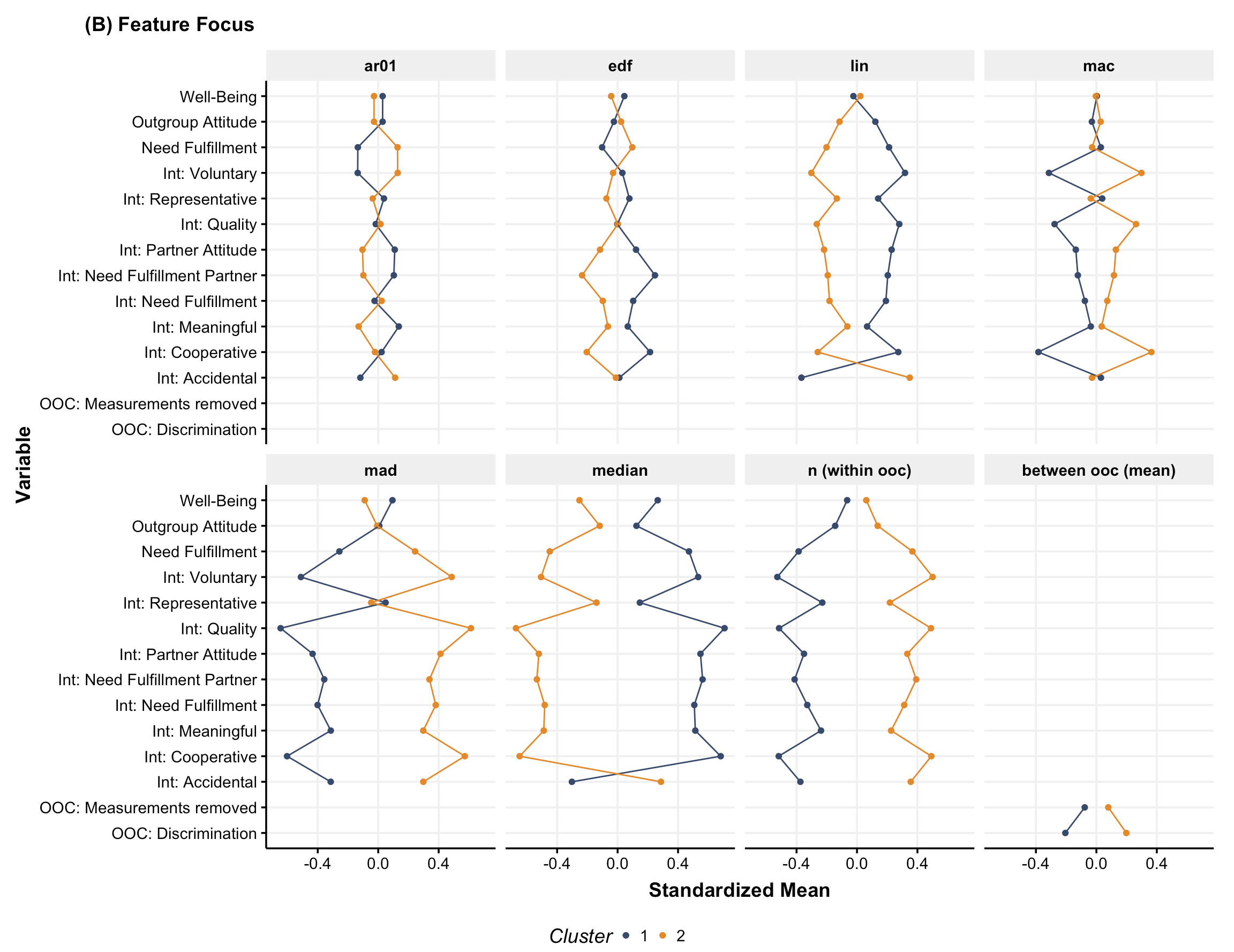
- Feature Extraction: We summarized each participant’s data using meaningful psychological features like variability, linear trends, and instability.
- Feature Reduction: To handle the complexity of the data, we reduced its dimensionality using techniques like Principal Component Analysis (PCA).
- Clustering: Using k-means clustering, we grouped participants based on similarities in their extracted features.
- Interpretation: The results revealed two distinct groups—one with more positive, stable experiences and another facing more challenges and variability.
Why This Matters
The ability to identify distinct patterns of psychological development has far-reaching implications. For researchers, it offers a way to make sense of large, complex datasets. For practitioners, it provides insights that can guide targeted interventions, such as identifying individuals who may need additional support.
Tools and Accessibility
To help others adopt this method, we’ve made the tools and code available:
- R Package: Automate feature extraction and analysis available here.
- Tutorials: Step-by-step guides for applying the method to your own data available here.
- Interactive Visualizations: Explore clustering results dynamically here.
What’s Next?
This work highlights the potential of feature-based clustering to human time series research. By capturing the nuances of how experiences unfold over time, it opens new avenues for understanding the dynamics of health, well-being, and human development. We are also working on an intuitive no-code application that lets users generate direct data insights including time series clustering at The DataFlow Company.
For more details, you can access the full article here: